
Rethinking Resilience — Why Redundancy Alone Isn’t Enough
When the Cloud’s Brain Fails
Business continuity is the benchmark of cloud success. Enterprises, service providers, and industrial operators all depend on digital infrastructure that must remain operational, regardless of where it’s hosted or who manages it.
But continuity depends on more than just redundant hardware. Even sophisticated cloud environments, built with redundant hardware and distributed architectures, can experience catastrophic outages that halt critical applications and services.
In many cases, the data centers themselves appear perfectly healthy. Power, cooling, and compute resources all function normally. Yet operations can grind to a halt. The reason? Failures can occur above the data plane — within the layers that control, orchestrate, and manage the cloud itself.
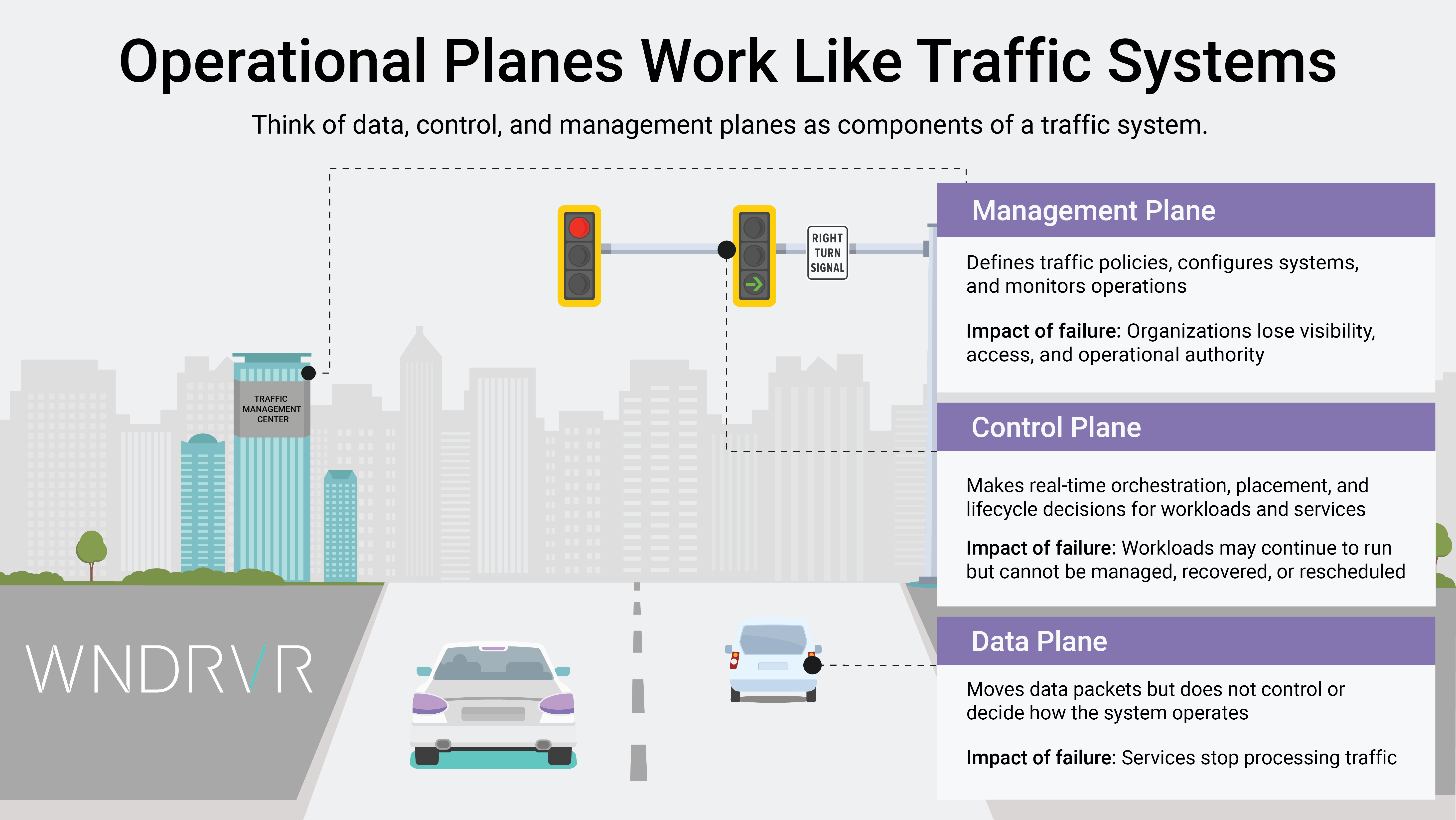
Thinking About Resilience at Another Level
It’s easy to assume that cloud outages are caused by hardware failures, network faults, or power disruptions. But many incidents stem from something far less visible: failures in the software layers that coordinate and manage cloud operations.
We see it in several well-documented cases. Misconfigured automation workflows, corrupted metadata, or faulty global configuration updates prevent applications from locating healthy databases, authenticating users, or routing traffic — even though the underlying compute and storage resources functioned normally.
In other words, the infrastructure was fine. The orchestration was not.
These types of failures occur in the control plane and management plane: the cloud’s “brain.”
When these layers malfunction, the cloud loses its ability to schedule, route, authenticate, or recover. The effects can cascade rapidly across services and regions.
Importantly, these disruptions are not caused by cyberattacks or physical infrastructure breakdowns. They are software-driven control- and management-plane issues. That demonstrates the fragility of continuity strategies when the cloud’s upper planes are not designed for resilience.
Resiliency Is More than Redundancy
For years, the cloud industry has largely equated resilience with redundancy: mirror the servers, replicate the storage, stretch the network, add more clusters. These steps are important. However, they only protect the data plane, which is the layer responsible for executing workloads.
True resiliency goes beyond keeping workloads alive. It ensures that the cloud can still orchestrate, authenticate, configure, and recover when unexpected conditions arise. That requires protecting all three operational planes: data, control, and management.
When the upper planes falter, redundant hardware effectively becomes useless. There may be plenty of compute capacity and healthy storage, but the system cannot function without the ability to route traffic, authenticate users, or update configurations.
It’s the equivalent of having a backup power plant but no operational control room to activate it.
This is why cloud continuity demands an architectural approach that protects far more than servers or disks. Without resilient control and management planes, infrastructure availability devolves into uptime without operational continuity.
Hidden and Unexpected Points of Failure
Centralized control and management simplify operations—until they don’t. Hyperscale cloud environments often rely on automated pipelines and global orchestration to push configuration changes, route traffic, enforce policies, and synchronize identity services across large, distributed footprints. In such architectures, prioritizing scale and uniformity over local independence can significantly expand the blast radius of control- and management-plane failures.
While powerful, this centralization can create an unexpected single point of failure. If an automation script propagates an error globally, or if a control-plane service becomes unstable, the impact may cascade across multiple regions or services. And it may happen within minutes.
In such circumstances, workloads may be fully operational, yet unreachable. Storage may be intact, yet undiscoverable. Authentication may be online, yet inaccessible.
As deployments scale, the control and management layers become the critical points of operational dependency. A fault can disconnect systems, freeze orchestration, or disrupt user access, even when the underlying infrastructure remains healthy.
Business continuity, therefore, depends not just on where data resides but on how control is distributed and safeguarded across the entire cloud environment.
Business Continuity as the Guiding Principle
For industries that rely on real-time operations — telecommunications, manufacturing, aerospace, automotive, healthcare — continuity is more than a performance metric. It is a fundamental business requirement. These environments can’t wait for global routing to recover or for authentication fixes to propagate. They need systems that work even during central failures.
Business continuity means maintaining control, visibility, and autonomy regardless of where disruptions occur. It’s the ability to keep the business running that matters, not merely keeping infrastructure online. Doing so avoids revenue loss, erosion of customer confidence, and the downstream risk of churn.
Achieving this level of continuity requires a new architectural mindset: one that extends resilience beyond redundant hardware to include the data, control, and management planes that collectively determine how a cloud operates under pressure.
Because in an era defined by digital dependence, the real measure of cloud resilience is the ability to continue functioning when the unexpected happens.
Explore how Wind River Private Cloud Suite protects all three operational planes to ensure true business continuity.
Wind River Blog
The Wind River Blog is made up of a variety of voices: executives, technologists and industry enthusiasts. We hope to foster conversations and encourage the sharing of insights regarding the evolving landscape of intelligent, connected systems with our ecosystem of customers, partners and colleagues.